Исследователи Яндекса разработали новую нейросетевую архитектуру для работы с табличными данными
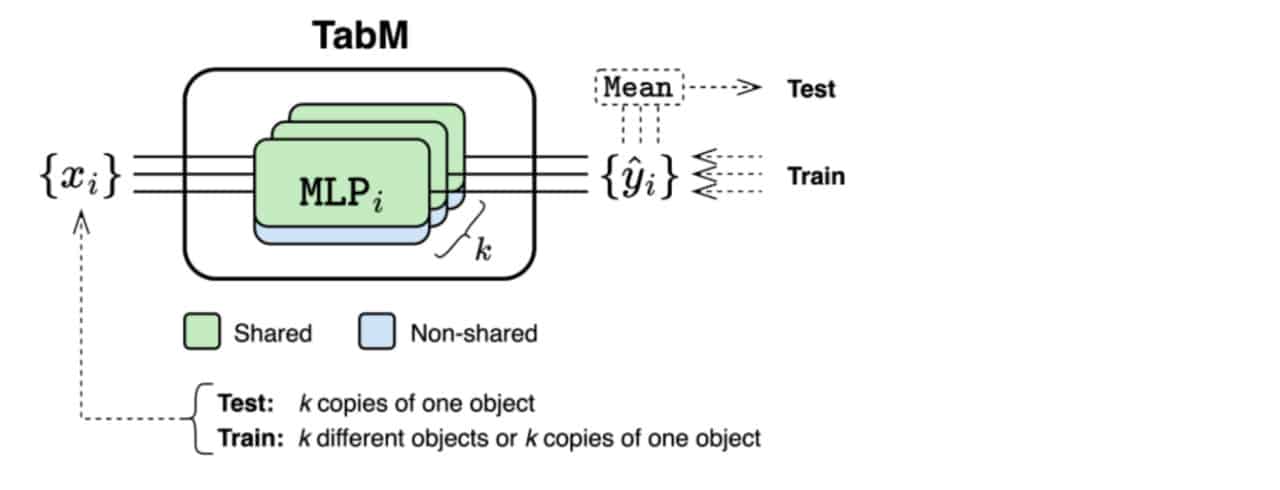

Общая схема TabM / © Yury Gorishniy et al.
Исследователи Яндекса разработали новую нейросетевую архитектуру для работы с табличными данными
Научная работа о модели была представлена на ICLR — одной из крупнейших в мире конференций по искусственному интеллекту. Статья также опубликована в архиве научных статей препринтов Корнеллского университета. Сама архитектура выложена в открытом доступе на GitHub.
Классические модели градиентного бустинга на решающих деревьях (CatBoost, XGBoost, LightGBM) традиционно считались стандартом для работы с табличными данными. В последние годы для этих задач также активно разрабатываются нейросетевые архитектуры — от простых многослойных перцептронов (MLP) до более сложных моделей на основе трансформеров и retrieval-механизмов. При этом вопросы стабильности и эффективности новых методов на широком спектре табличных задач, а также возможности их практического применения, оставались открытыми.
В своей работе исследователи из лаборатории Yandex Research обратили внимание на потенциал улучшения MLP за счет параметро-эффективного ансамблирования. Они предложили архитектуру TabM, созданную на основе многослойного перцептрона с применением модифицированной техники BatchEnsemble. Внутри одной нейросетевой модели формируется несколько виртуальных подмоделей с частично общими параметрами, чьи предсказания затем усредняются.
Такой подход позволил TabM не только превзойти базовые MLP и более сложные современные нейросетевые решения для табличных данных, но и достичь качества, сопоставимого или превосходящего лучшие классические модели градиентного бустинга. Тестирование проходило на 46 наборах данных, причем среднее место TabM в тестах оказалось между первым и вторым (усредненно 1,7).
Это очень хороший результат, потому что в норме подобные модели делают точные прогнозы только для некоторых наборов данных, под которых их оптимизировали при разработке. Обычная модель редко занимает первые и вторые места сразу в десятках наборах данных. Например, ближайший конкурент TabM в среднем занимал места, ближе к третьему (2,9).
То есть TabM оказалась лидером по универсальности. Это важно, поскольку разрабатывать специализированную модель под каждый новый набор данных долго, дорого и не всегда гарантирует наилучшее качество. В отличие от таких решений, архитектура TabM универсальна: ее можно применять без глубокой донастройки. Таким образом, специалисты получают новый эффективный и более легкий в использовании инструмент.
На практике TabM уже применили на Kaggle. Это платформа международных соревнований по анализу данных и машинному обучению от Google. Среди задач, для которых применяли TabM, было, например, предсказание выживаемости пациентов после трансплантации костного мозга. Сперва, при обучении, в модель загружали таблицу с данными пациентов с аналогичными диагнозами, в которых было указано — выжил пациент или нет. Затем обученная модель получала данные по нынешним пациентам и делала прогноз по их выживанию.
За шесть лет Yandex Research представила в общей сложности восемь научных статей по глубокому обучению моделей для работы с табличными данными. Эти работы получили более 1900 цитирований в других исследованиях, а статьи по ним были приняты на самые влиятельные конференции по нейросетям, в том числе NeurIPS, ICLR и ICML. Источник материала и фото: "Naked Science"






